DataWhale AI 冬令营
4 min
Datawhale AI 冬令营
task 1.1
动手学定制你的专属大模型
1. 定制大模型
主要的技术
只列举三个
微调(Fine-tuning):
- 对预训练模型进行再训练,让其适应特定任务。
提示工程(Prompt Engineering)
像前段时间很火的 提示工程:Thinking-Claude
- 不改变模型参数,通过设计高效的提示优化模型输出。
- 两种prompt技术
- 上下文学习(In-Context Learning, ICL)
- 将任务说明及示例融入提示文本之中,利用模型自身的归纳能力,无需额外训练即可完成新任务的学习。
- 思维链提示(Chain-of-Thought, CoT)
- 引入连贯的逻辑推理链条至提示信息内,显著增强了模型处理复杂问题时的解析深度与广度。
- 上下文学习(In-Context Learning, ICL)
Embedding辅助给LLM外接大脑
- 接入更多知识库向量
何为垂类大模型
高中生 ( 通用大模型 ),灌输 知识偏好 (数据集)塑造世界观,长大成 职业选手(垂类大模型 )
在通用的大模型的基础上,针对某一特定领域做微调,成为某一领域的专家
定制垂类大模型 = 优质数据集 + 开源大模型
2. 微调技术
这次定制 llm 实践用到的是微调技术, 本次使用
讯飞星辰Maas平台。
微调技术
什么是微调
- 是一种技术,用特定的小规模数据集再次训练,使得模型适应特定任务。
如何微调
全量调参
全量精调
- 全量调参是将模型的所有参数都进行微调
轻量化调参
LoRA
最常用
- LoRA 是通过低秩矩阵分解,在原始矩阵的基础上增加一个旁路矩阵,然后只更新旁路矩阵的参数。
Adapter
- 不改变原模型主体结构,在特定位置插入适配器进行训练
Prompt Tuning
- 优化输入而不是优化大模型本身
微调用到的数据集
格式要求:
Alpaca格式什么是 Alpaca
- Alpaca 是 一个微调后的模型。模型包含数据集。
- 格式为
json,每条记录对应着一条训练样本
为什么要用到 Alpaca 格式微调
高效,通用,灵活
高效
“指令-输入-输出”三元组,这种格式的数据训练可以显著提高模型的指令遵循能力
基本构成格式
- instruction:
- 用户希望模型执行的指令。
- input(可为空):
- 提供给指令的上下文或输入。
- 若不需要上下文,则为空字符串。
- output:
- 指令的目标响应或结果。
- instruction:
eg.(指令监督微调样例数据集){ "instruction": "这位是?", "input": "", "output": "这位是眉庄姐姐。" },
通用
- 训练产出的数据集可以跨领域使用。
灵活
- 修改输入指令就可以改变输出,而不用修改模型本身。
信息记录


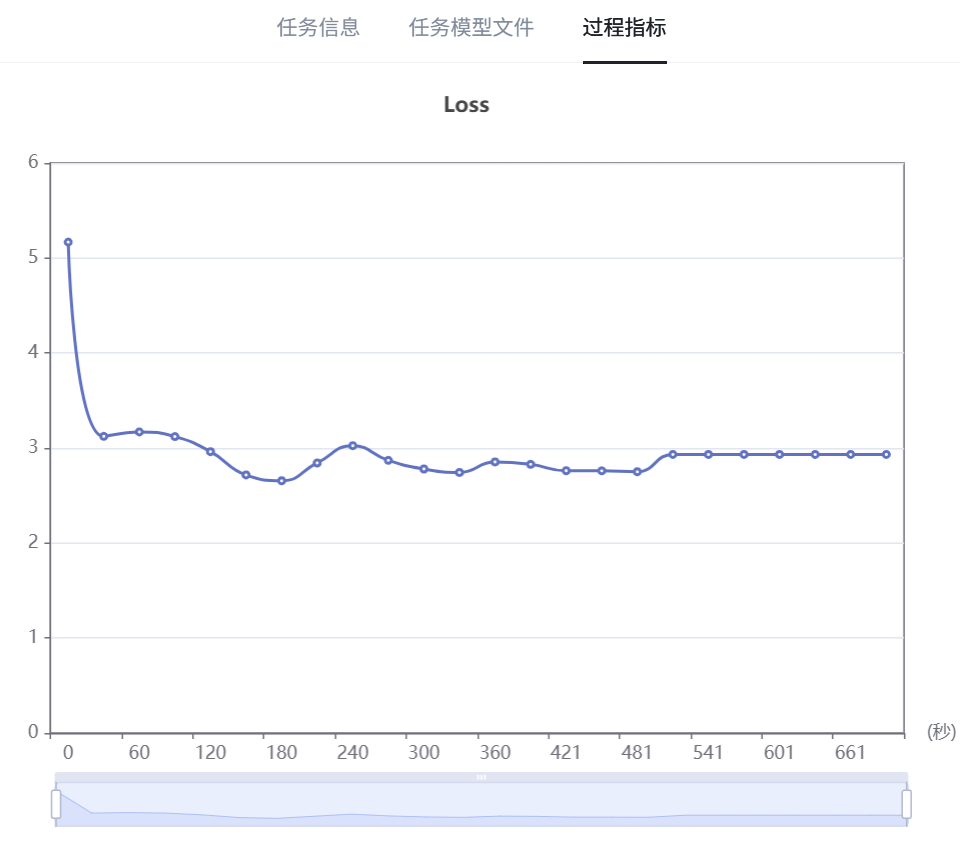
效果记录
token 监控 星火大模型精调平台
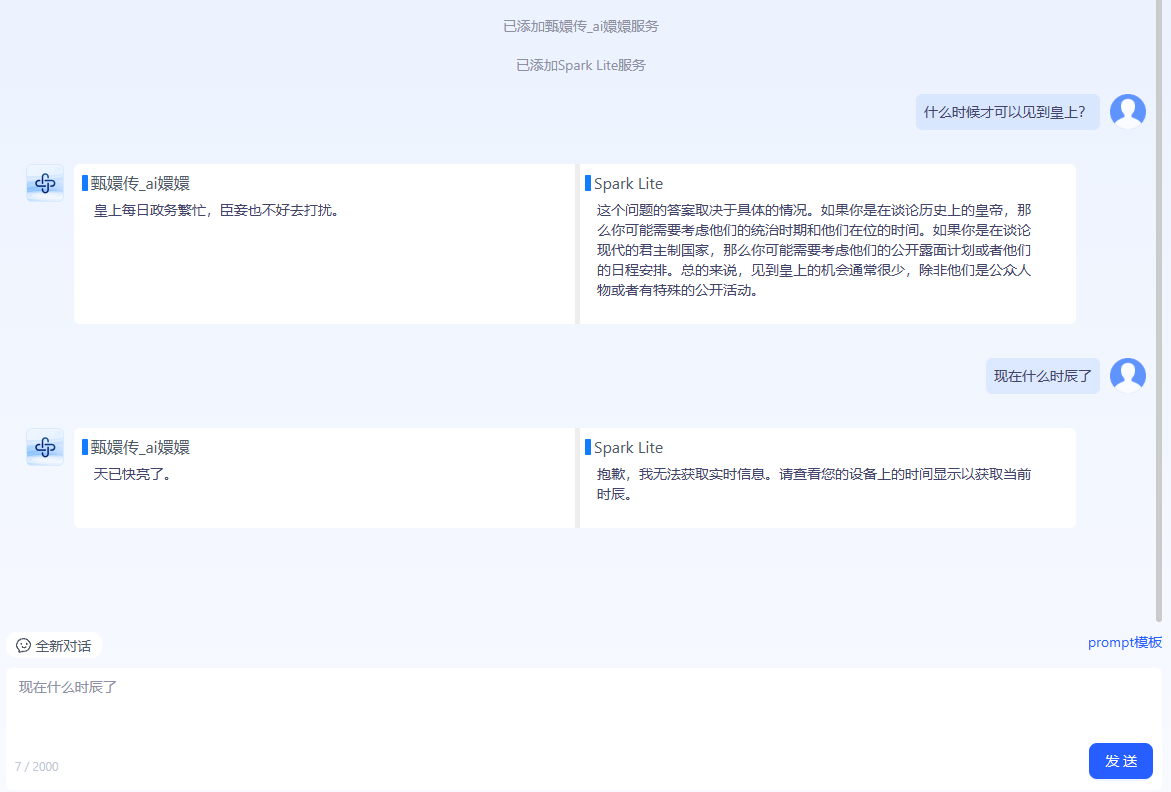
直播记录
- 人工智能三大马车
- 数据、算法、算力