大模型基础知识
01_大模型基础知识
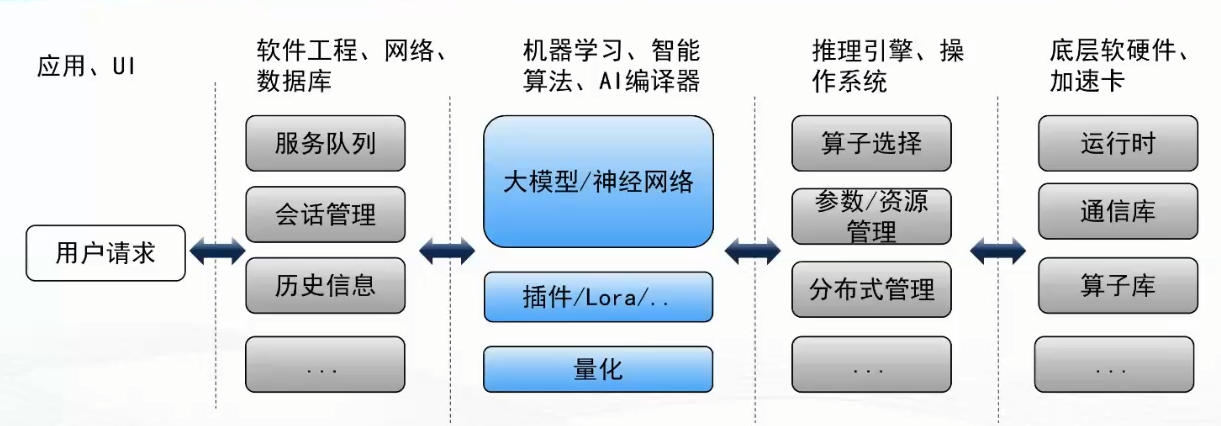
应用层级
什么是大模型
- 是机器模型
- 有大规模参数
- 有复杂计算结构
- 有深度神经网络
为什么需要大模型
传统模型的局限
- 很难找到合适的数学公式
人工神经网络可以解决这类问题
模拟生物神经系统
神经网络是什么
神经元
线性计算
信号传输
- 权重
- 偏移
非线性计算
决定是否激活
神经网络如何决策
画线分割
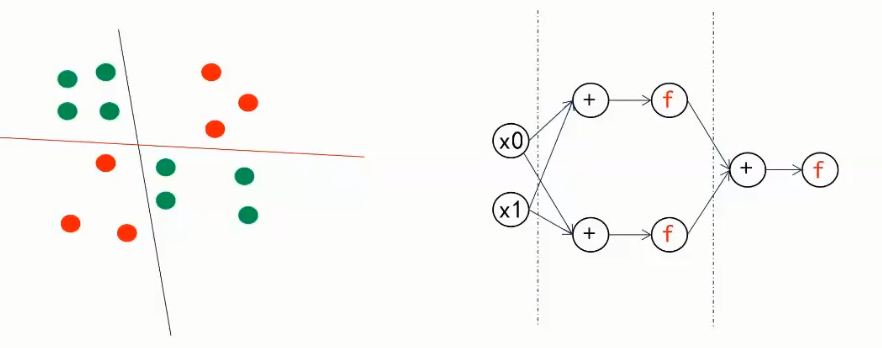
万能近似定理
三层可以模拟任意决策边界
- 输入层
- 隐藏层
- 输出层
训练 VS 推理
模型参数调整
- 训练
- 目的是准确预测
- 定义损失函数,慢慢调整,使得“线”画的准确
- 调整参数(方式:梯度下降-求导)
- 目的是准确预测
- 推理
- “线”画好了(使用训练的参数)
- 对数据进行预测
- 训练
不同深度的神经网络
- 目的
- 相比于“三层”
- 用较少的参数捕捉更为复杂的结构
- 特殊的结构
- Transformer,CNN, RNN
- 目的
大模型核心算子
矩阵乘(线性计算)
输入有 3 个点( 的行向量)。
中间的输出有 4 个点(我 的行向量)。
中间的连线代表权重矩阵 ()
第1根线(连向输出1) 填在 (第1行, 第1列)
第2根线(连向输出2) 填在 (第1行, 第2列)
…以此类推。
激活函数(非线性计算)
需要梯度下降
目的是找到最低点
这两个算子的关系
- 如果没有激活函数(只有线性变换),你就像是在叠一张平整的纸,怎么叠它都还是一张平面。
- 有了激活函数(非线性变换),你就可以把这张纸折叠、弯曲。
目前,这个结构有一个问题是,输入固定,输出一定的一定的(数学公式决定的),但对于大语言模型来说,我们希望所问的问题不同,得到的回答也是不同的。所以之后需要引入
transformer
大模型有多大
- fp16(一个参数2字节),1B(十亿个参数)
- 这个模型大小:2*10^9^ = 2G
大模型优化
- 许多神经元不会被激活,所以有优化空间
02_大模型原理与结构
大模型 vs 传统模型
传统模型
- 输入-输出都为向量(vector2vector)
- 如卷积神经网络
- 输入-输出都为向量(vector2vector)
大模型
- sequence to sequence : 输入输出为文字
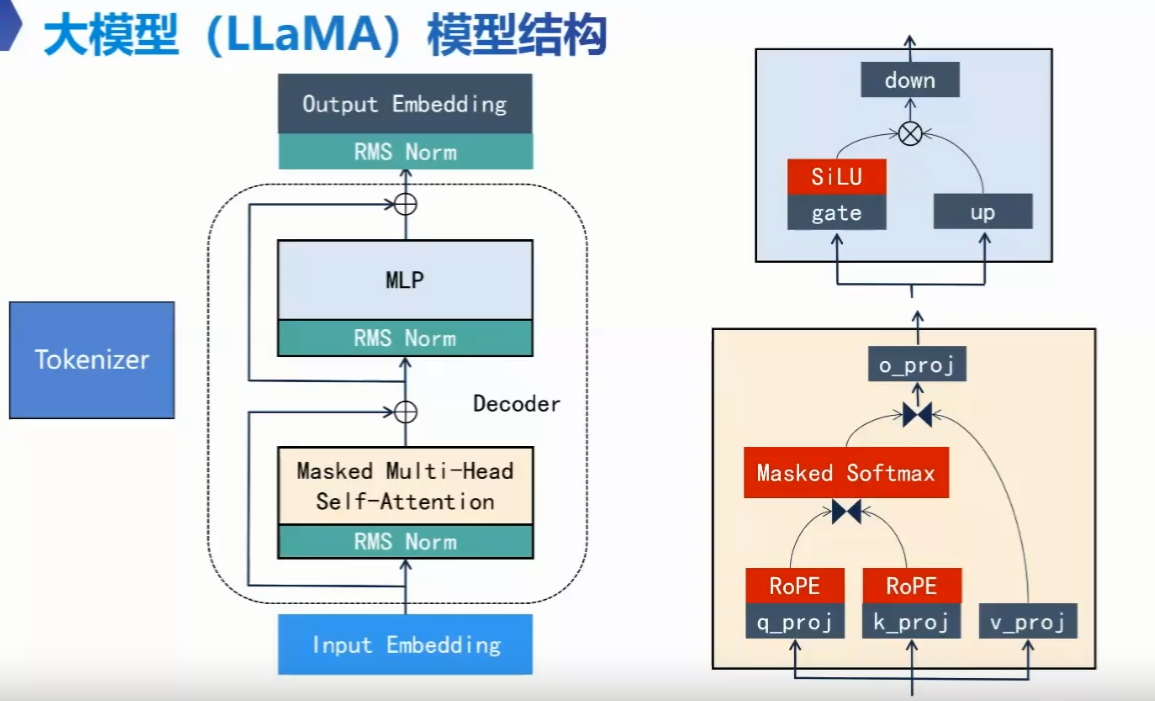
LLaMA 模型
Meta 开发的
整体流程图
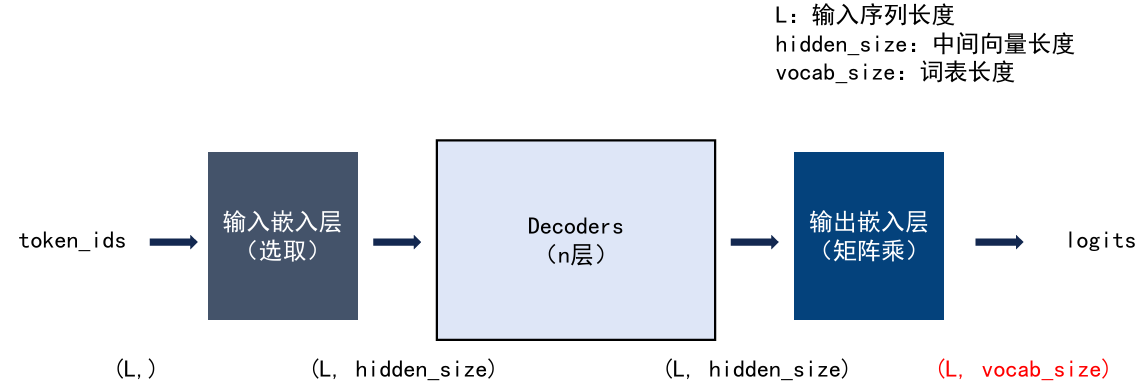
具体步骤
输入基础设施层
Tokenizer(翻译官 —— 离线工具)
- 它甚至不参与任何矩阵乘法。它只是拿着一张固定的 BPE 表,把“Hello”翻译成
15496。
- 物理地位:它是模型推理前的预处理步骤,不含参数学习。
- 它甚至不参与任何矩阵乘法。它只是拿着一张固定的 BPE 表,把“Hello”翻译成
Embedding(辞典 —— 输入基座)
- 虽然它有参数,但它不具备“处理逻辑”的能力。它的作用只是查表,把 ID 变成向量。
- 物理地位:它是进入加工厂之前的“原材料准备间”。
步骤 处理过程 核心本质 1. Tokenize 文本 ID 符号化:给万物一个编号。 2. Embedding ID 向量 空间化:通过“查表”把编号映射到 4096 维空间,让语义相近的词在几何上靠近
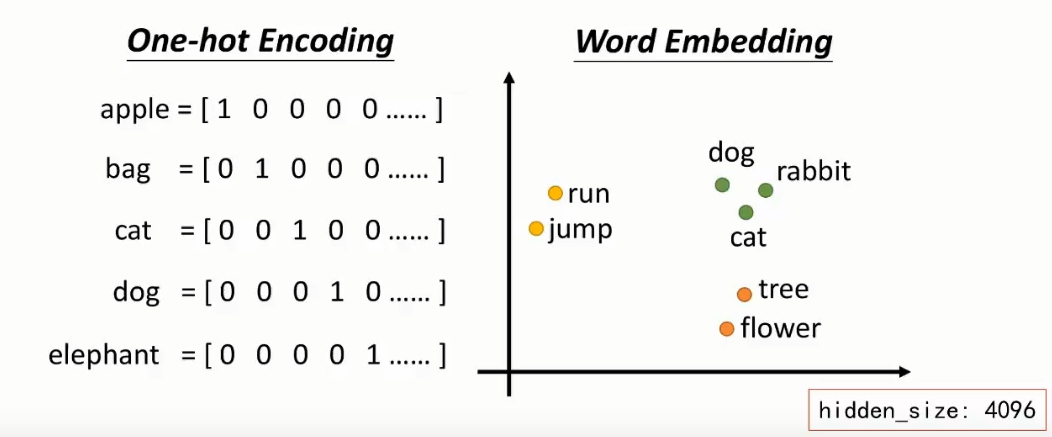
不足
但这一层无法处理一样的字。
比如
道可道,比如苹果 出现在“苹果手机”还是“红富士苹果”里,它的 Embedding 向量都一样。
- 所以引入自注意力层(在 decoder 层里)
- 根据周围的词来判断苹果的含义
Decoder 层
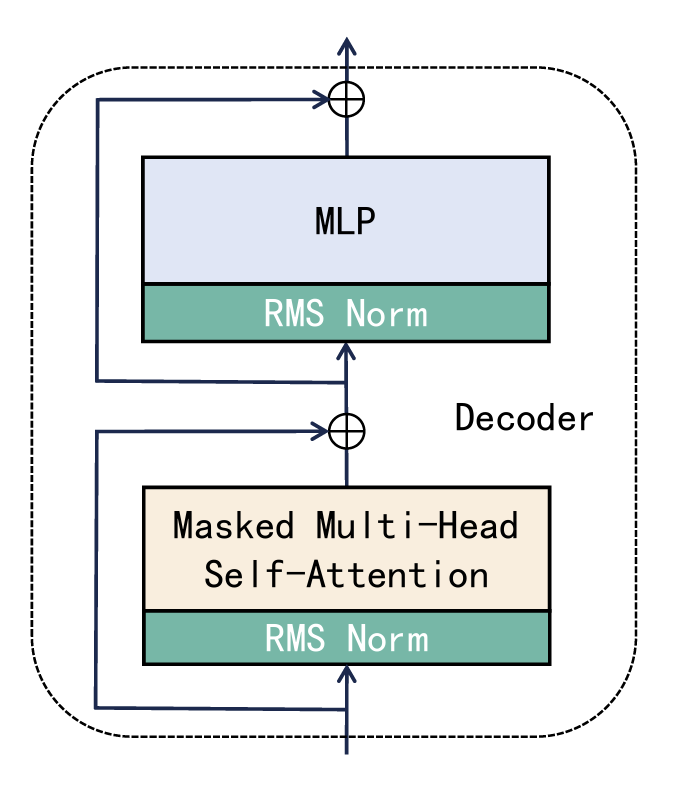
RMS Norm 层
- 为什么要做 RMS( 层归一化)
- 经过成百上千次的矩阵乘法(因为会循环 decoder),数据中的数值可能会变得极大或者极小。
- 这会导致模型无法继续学习。
- 很多激活函数在数值太大或太小时会进入“饱和区”(比如变平了)
- 导致模型对微小的变化不再敏感。
- 经过成百上千次的矩阵乘法(因为会循环 decoder),数据中的数值可能会变得极大或者极小。
- RMSNorm 的作用
- 就像是一个**“稳压器”**。把输入的向量稳压
- 它在每一层计算结束时,把 4096 维向量的分布重新“拉回”到一个稳定的标准范围
- RMSNorm 则更简化,只关注均方根。
- 就像是一个**“稳压器”**。把输入的向量稳压
Self-Attention 层
QKV 交互后,每个词都吸收了周围环境的信息。让“苹果”去观察周围的词,根据上下文来动态更新自己的向量。
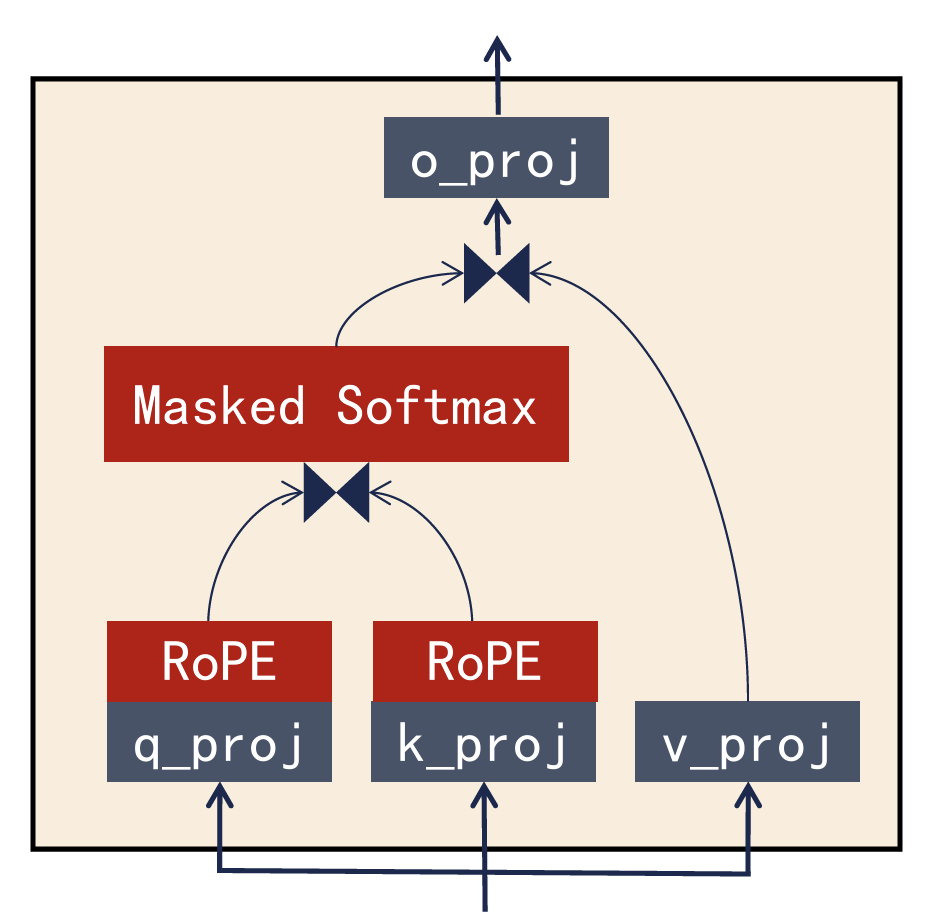
三路并行投影
q_proj: 生成 Query(查询)。它代表:“我这个词正在寻找什么样的上下文?”
k_proj: 生成 Key(键)。它代表:“我这个词有什么特征,欢迎别人来查我。”
v_proj: 生成 Value(值)。它代表:“如果我被选中了,我能贡献出的实际信息内容是什么?”
位置注入 (RoPE)
- Q 和 K 经过了 RoPE (旋转位置编码) 处理。
- 一行行,行行行。两个半句的行意思是一样的。即
- 需要 RoPE 处理。
- 给向量加上“位置感”。它通过数学旋转的方式,让模型知道词与词之间的相对距离。
Q 与 K 进行**点积(Dot Product)**运算
- 公式:
- 逻辑:拿我的 Q 去和全句所有词的 K 做点积。
- 结果:得到一个“相关性矩阵”,数值越高,表示两个词关系越深。
权重归一化 (Masked Softmax)
- Softmax: 把刚才计算的关联度分数转化为 0 到 1 之间的概率(总和为 1)。
- 对数字做归一化处理,使得相加为100%(如“可”字)
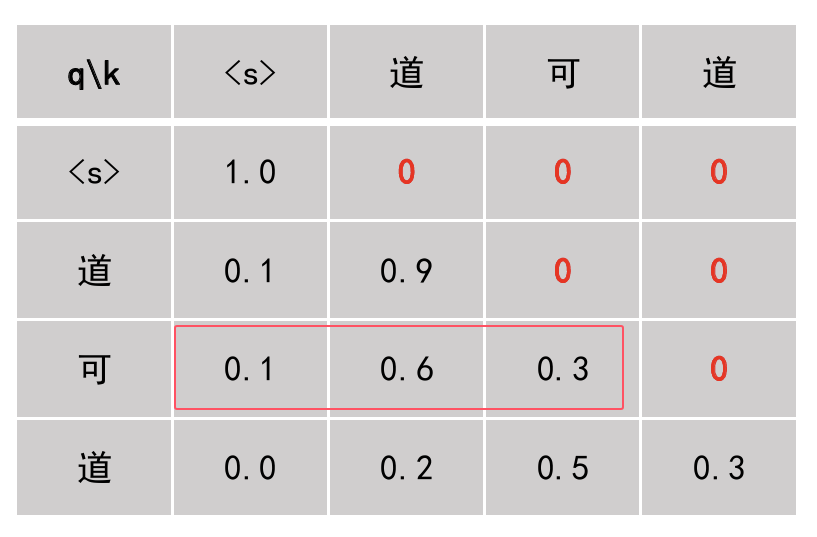
- 对数字做归一化处理,使得相加为100%(如“可”字)
- Masked(掩码): 这是 Decoder 的核心。它挡住了“未来的词”,确保模型在预测当前词时,只能看到它之前的词,不能作弊看后面的词。
- Softmax: 把刚才计算的关联度分数转化为 0 到 1 之间的概率(总和为 1)。
信息聚合 (Value Aggregation)
公式:
逻辑:根据第一步算出的相关性权重,把各个词的 V(财富)捞过来。
结果:当前词吸收了周围环境的信息。例如,“苹果”在“苹果手机”语境下,吸收了“电子产品”的 V,从而完成了语义更新。
最终整合 (o_proj)
- 这是注意力层的最后一步。
- o_proj (Output Projection): 负责把多头注意力(多个专家视角)搜集到的所有信息进行一次矩阵乘法融合
- 之后将其重新映射回标准的 4096 维空间,方便输出给后续的残差层和 MLP。
- 这是注意力层的最后一步。
MLP 层 (多层感知器层)

为什么需要(ai解释)
存储知识:自注意力层是在“看当前句子”,而 MLP 的矩阵参数里存储的是模型在预训练阶段背下的“海量知识”。
非线性变换:如果没有 MLP 里的激活函数,模型就只是在做无聊的线性累加,永远学不会复杂的逻辑。
特征细化:通过放大到 11008 维,模型可以对语义进行更精细的“雕琢”。
做了什么
放大 门控 缩小
数据进入 MLP 后,会经历一个“先膨胀、再加工、后压缩”的过程:
- Up Proj (向上投影):
- 动作:将 4096 维的向量放大到约 11008 维(通常是输入的 2.7 倍左右)。
- 目的:把信息撒得更开,以便模型在更高的维度里发现细微的特征。
- Gate Proj (门控投影) & 激活函数 (SiLU):
- 动作:这是 MLP 的核心“闸门”。它产生一组权重,通过激活函数后,决定哪些放大的特征是有效的。
- 逻辑:它和 Up Proj 的结果做逐元素相乘。只有被“门控”认可的信息才能留下来。
- Down Proj (向下投影):
- 动作:将加工后的 11008 维向量重新压缩回 4096 维。
- 目的:总结特征,对齐维度,方便交给下一层。
- Up Proj (向上投影):
Residual Add (再次残差相加)
- --- 以上过程循环 32 次 ---
输出嵌入层
- 是根据 4096 维向量反推词 ID。
- 在很多模型中,为了节省参数,输入嵌入矩阵和输出嵌入矩阵其实是同一个矩阵的转置
tie_word_embeddings: true说明输出嵌入层和输入嵌入层用的参数是一样的